为什么用 Jupyter notebook ?
平时用的最多的 Python 的 IDE 是 Spyder,在编辑器中编辑代码并在 IPython 中运行。但后来在处理一些特定的问题时很不方便,比如运行一些脚本时,希望能够保存每次运行的结果;写代码的时候希望能够记录下一些思路,当然可以用注释,但是这样显得很不整洁;拿到一批数据时,总是希望先可视化,试图发现一些规律,并把结果都保存下来。这时候用 IPython 就不那么方便了。
Ipython更适合写好代码后一次运行,而 Jupyter notebook 更像是一个笔记本,可以随时记录,可以直接运行代码直接显示结果,能将思路都完整保留下来,支持 Markdown 语言,很多人用它代替 PTT 做学术汇报。
Jupyter notebook 使用技巧
单元前面的原色表示不同的状态,蓝色是 命令模式,可以对单元进行操作,包括插入新的单元,删除不想要的单元,也可以选择不同的输入状态;绿色是 编辑模式,可以编辑代码或者文字,用 ‘Enter’ 和 ‘ESC’ 可以切换不同状态。
通过快捷键操作,提高工作效率,也比较酷。下面是我常用的一些快捷键:
命令模式
- m: markdown 输入状态
- y: 代码输入状态
- Shift-Enter : 运行本单元,选中下个单元(如果没有就新建一个单元)
- Ctrl-Enter : 运行本单元
- Alt-Enter : 运行本单元,在其下插入新单元
- a: 在上方插入新单元
- b: 在下方插入新单元
- x: 剪切选中的单元
- c: 复制选中的单元
- Shift-V : 粘贴到上方单元
- v : 粘贴到下方单元
- z : 恢复删除的最后一个单元
- dd : 删除选中的单元
- Shift-M : 合并选中的单元
编辑模式
- Shift-Enter : 运行本单元,选中下个单元(如果没有就新建一个单元)
- Ctrl-Enter : 运行本单元
- Alt-Enter : 运行本单元,在其下插入新单元
- Ctrl-Home : 跳到单元开头
- Ctrl-End : 跳到单元开头
其他和普通的编辑器都一样。
Markdown 简介
Markdown 是这一种标记语言,语法简洁明了,容易理解,几乎感觉不到语法的存在,GitHub 和很多博客平台都支持这种语法。平时我会用 Atom 编辑器,不要用它自带的 Markdown 插件,太不好用了,推荐 markdown-preview-enhanced,功能很强大。这里对语法不做介绍,可以看以下的链接:
Jupyter notebook 演示
载入相关库
import numpy as np
from sklearn import datasets
import pandas as pd
# 将iris数据转换为Dataframe格式
iris = datasets.load_iris()
iris_X = iris.data
iris_y = iris.target
irisdata = np.concatenate((iris_X, iris_y.reshape(-1, 1)), axis=1)
columns_label = ['Sepallength', 'Sepalwidth', 'Petallength', 'Petalwidth', 'Species']
y_label = iris.target_names
irisDf = pd.DataFrame(data=irisdata,
columns=columns_label)
for i in xrange(3):
irisDf['Species'].replace(i, y_label[i], inplace=True)
查看数据
irisDf.head()
| Sepallength | Sepalwidth | Petallength | Petalwidth | Species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
描述数据
irisDf.describe()
| Sepallength | Sepalwidth | Petallength | Petalwidth | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.054000 | 3.758667 | 1.198667 |
| std | 0.828066 | 0.433594 | 1.764420 | 0.763161 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
绘图
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="darkgrid", color_codes=True)
%matplotlib inline
sns.pairplot(irisDf, hue="Species")
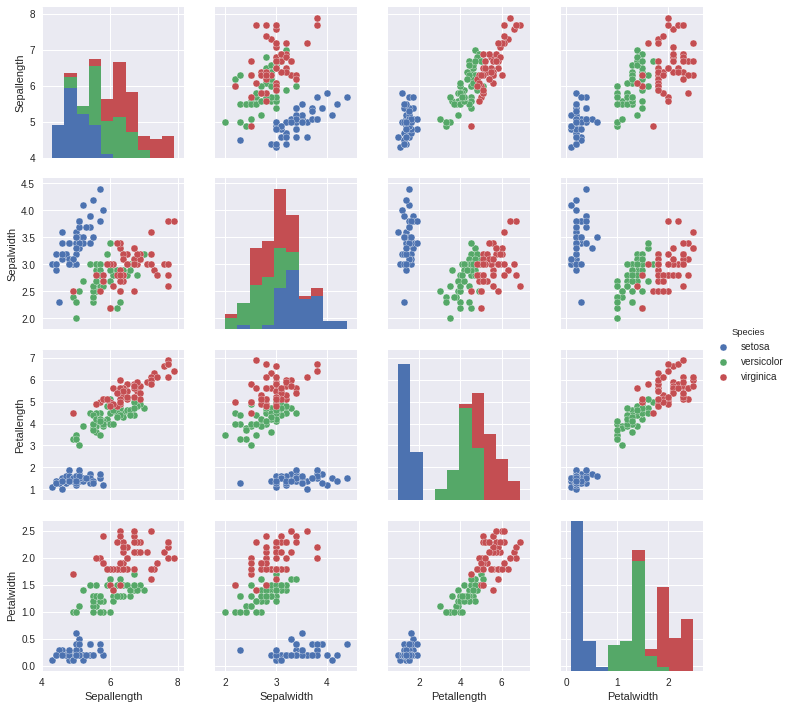
可以看到,Jupyter notebook 对于数据可视化相当方便,能保存每一步的结果,思路很清晰;markdown 语法也比代码注释要美观的多。
保存
Jupyter notebook 直接保存为 .ipynb 文件,也可以保存为 .py .html .md .pdf 文件,保存为pdf我没有试过,可以看下下面这个链接:
MAKING PUBLICATION READY PYTHON NOTEBOOKS
总结
Jupyter notebook 功能很强大,不仅能运行 Python 代码,还能安装不同的 kernal 运行其他代码,其他功能我自己也在摸索中,目前我自己常用的就是这些了。
本作品采用 知识共享署名 3.0 中国大陆许可协议 进行许可。